1. 简介
Disruptor 是英国外汇交易公司为了解决交易系统高时延、低吞吐量而设计的并发队列。基于Disruptor开发的系统单线程能支撑每秒600万订单,2010年在QCon演讲后,获得了业界关注。2011年,企业应用软件专家Martin Fowler专门撰写长文介绍。同年它还获得了Oracle官方的Duke大奖。
2. 背景知识
在介绍 Disruptor 之前,我们需要复习一下相关的背景知识,并分析 juc 包中内置队列的性能问题。
2.1 内存模型和 Java GC
2.1.1 内存模型
图Fig 1是计算的基本结构。L1、L2、L3分别表示一级缓存、二级缓存、三级缓存,越靠近CPU的缓存,速度越快,容量也越小。所以L1缓存很小但很快,并且紧靠着在使用它的CPU内核;L2大一些,也慢一些,并且仍然只能被一个单独的CPU核使用;L3更大、更慢,并且被单个插槽上的所有CPU核共享;最后是主存,由全部插槽上的所有CPU核共享。
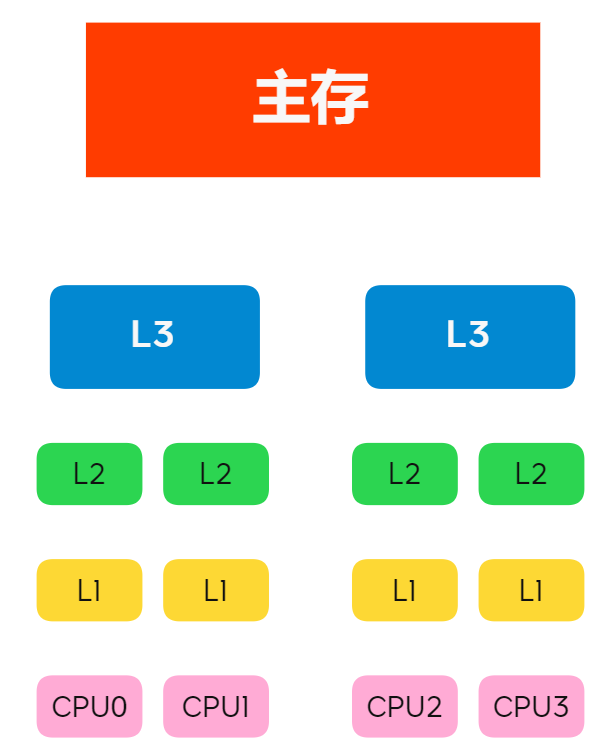
Fig. 1. 计算机内存模型
当CPU执行运算的时候,它先去L1查找所需的数据、再去L2、然后是L3,如果最后这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要尽量确保数据在L1缓存中。
另外,线程之间共享一份数据的时候,需要一个线程把数据写回主存,而另一个线程访问主存中相应的数据。下表给出了 CPU 访问不同层级数据所耗费的时间,CPU 从主存中读取数据的时间比从 L1 中慢了 2个数量级。
Table. 1. CPU 访问不同层级数据的时间成本
| 层级 | 大约需要的 CPU 周期 | 大约需要的时间 |
|---|---|---|
| 主存 | - | 60 ~ 80 ns |
| L3 | 40 ~ 45 cycles | 15 ns |
| L2 | 10 cycles | 3 ns |
| L1 | 3 ~ 4 cycles | 1ns |
| 寄存器 | 1 cycles | - |
缓存行
Cache是由很多个cache line组成的。每个cache line通常是64字节,并且它有效地引用主内存中的一块儿地址。一个Java的long类型变量是8字节,因此在一个缓存行中可以存8个long类型的变量。
CPU每次从主存中拉取数据时,会把相邻的数据也存入同一个cache line。
在访问一个long数组的时候,如果数组中的一个值被加载到缓存中,它会自动加载另外7个。因此你能非常快的遍历这个数组。事实上,你可以非常快速的遍历在连续内存块中分配的任意数据结构。
下面测试使用 cache line 特性的数据读取速度
1 | /** |
测试结果
Loop times: 12 ms
Loop times: 45 ms
2.1.2 Java GC
GC 会影响低时延系统的性能。分配的内存越多,GC 的压力越大。当对象的生命周期非常短或者永生时,GC 的效率最高。使用元数组预分配内存,对于 GC 来说它是永生的,这将大大降低 GC 的负载。
高负载下基于队列的系统会阻塞,这使系统处理速度下降。同时导致分配的对象比它们应该生存的时间长,从而提升到下一代的分区中(分代回收假说)。显然地,在两代之间复制对象会导致时延的抖动;除此之外,我们知道 jvm 在回收老年代的对象时,代价更加昂贵,当老年代对象多于某个阈值就会触发 GC,则发生 “stop the world” 的概率会增加。在大内存堆栈中,每次GC会导致系统暂停几秒。
2.2 锁与 CAS
2.2.1 加锁
现实编程过程中,加锁通常会严重地影响性能。线程会因为竞争不到锁而被挂起,等锁被释放的时候,线程又会被恢复,这个过程中存在着很大的开销,并且通常会有较长时间的中断,因为当一个线程正在等待锁时,它不能做任何其他事情。如果一个线程在持有锁的情况下被延迟执行,例如发生了缺页错误、调度延迟或者其它类似情况,那么所有需要这个锁的线程都无法执行下去。如果被阻塞线程的优先级较高,而持有锁的线程优先级较低,就会发生优先级反转。
LAMX Disruptor 论文中给出了使用锁和 CAS 的成本比较:调用一个函数,在循环中将 long 类型计数器递增 5 亿次,实验结果如 Table. 2。显然,多线程情况下使用 CAS 的竞争成本明显降低。
Table. 2. 竞争成本比较
| 方法 | 时间(ms) |
|---|---|
| 单线程 | 300 |
| 使用锁的单线程 | 10,000 |
| 使用锁的两个线程 | 224,000 |
| 使用 CAS 的单线程 | 5,700 |
| 使用 CAS 的两个线程 | 30,000 |
2.2.2 CAS(Compare And Swap)
CAS 操作是一种特殊的机器代码指令,它允许有条件地将内存中的一个字设置为原子操作,可以用 ==compareAndSwap(oldValue, newValue)== 表示。
2.3 ArrayBlockingQueue 分析
juc 包中提供了 Table. 3 几个线程安全的队列。
Table. 3. juc 内置线程安全队列
| 队列 | 有界性 | 加锁 | 底层结构 |
|---|---|---|---|
| ArrayBlockingQueue | 有界 | 加锁 | ArrayList |
| LinkedBlockingQueue | 可选有/无界 | 加锁 | LinkedList |
| ConcurrentLinkedQueue | 无界 | 无锁 | LinkedList |
| LinkedTransferQueue | 无界 | 无锁 | LinkedList |
| PriorityBlockingQueue | 无界 | 加锁 | Heap |
| DelayQueue | 无界 | 加锁 | Heap |
队列的底层一般分成三种:数组、链表和堆。其中,堆一般情况下是为了实现带有优先级特性的队列,暂且不考虑。
我们就从数组和链表两种数据结构来看,基于数组线程安全的队列,比较典型的是 ArrayBlockingQueue,它主要通过加锁的方式来保证线程安全;基于链表的线程安全队列分成 LinkedBlockingQueue 和 ConcurrentLinkedQueue 两大类,前者也通过锁的方式来实现线程安全,而后者以及上面表格中的 LinkedTransferQueue 都是通过 CAS 这种不加锁的方式来实现的。
通过不加锁的方式实现的队列都是无界的(无法保证队列的长度在确定的范围内);而加锁的方式,可以实现有界队列。在稳定性要求特别高的系统中,为了防止生产者速度过快,导致内存溢出,只能选择有界队列;同时,为了减少 Java GC 对系统性能的影响,会尽量选择 Array/Heap 格式的数据结构。这样筛选下来,符合条件的队列就只有 ArrayBlockingQueue。
ArrayBlockingQueue 有三个 int 类型成员变量:
- takeIndex:需要被取走的元素下标
- putIndex:可被元素插入的位置的下标
- count:队列中元素的数量
这三个变量很容易放到一个缓存行中,但是之间修改没有太多的关联。所以每次修改,都会使之前缓存的数据失效,从而不能完全达到共享的效果。比如生产者线程执行 add() 操作时,putIndex 发生改变,则消费者线程缓存中的 putIndex 失效,即整个 cache line 失效,需要重新从主存中读取,则无法利用 cache line 的特性,这就是“伪共享”。
jdk 1.8 后支持注解 ==@Contended== 进行缓存行填充,解决多线程伪共享问题。
3. Disruptor 设计方案
3.1 核心概念
- 环形缓冲区(Ring Buffer):环形缓冲区仅仅负责存储和更新从 Disruptor 中移动的数据(事件),为了避免伪共享,在这个数组的两端额外填充了若干空位。
- 序列(Sequence):Disruptor 使用序列确定某个特定组件的位置。类似于 AtomicLong,用于标记事件 id。所有生产者共用一个 Sequence,用于不冲突的将事件放到 RingBuffer 上。每个消费者自己维护一个 Sequence,用于标记自己当前正在处理的事件的id。
- 序列器(Sequencer):序列器是 Disruptor 的核心,该接口的两个实现(SingleProducerSequencer,MultiProducerSequencer)分别用于单生产者和多生产者场景,在生产者、消费者间进行快速、正确的数据传递。
- 序列屏障(Sequence Barrier):只有一个实现类为 ProcessingSequenceBarrier,用于协调生产者与消费者(如果某个 slot 中的事件还没有被所有消费者消费完毕,那么这个 slot 是不能被复用的,需要等待)。
- 事件(Event):从生产者到消费者的数据单元,没有特定的代码表示事件,通常由用户定义。
- 事件处理器(Event Processor):用于处理来自Disruptor的事件的主要事件循环并具有消费者序列的所有权。有一个称为 BatchEventProcessor 的单个表示,其中包含事件循环的有效实现,并将回调 EventHandler 接口的使用实现。
- 事件处理者(Event Handler):一个由用户实现的接口,代表 Disruptor 中的生产者、消费者。
- 等待策略(Wait Strategy):消费者等待下一个可用事件的策略,Disruptor自带了多种WaitStrategy的实现,可以根据场景自行选择。
下图是一个使用 Disruptor 的高性能核心服务示例。
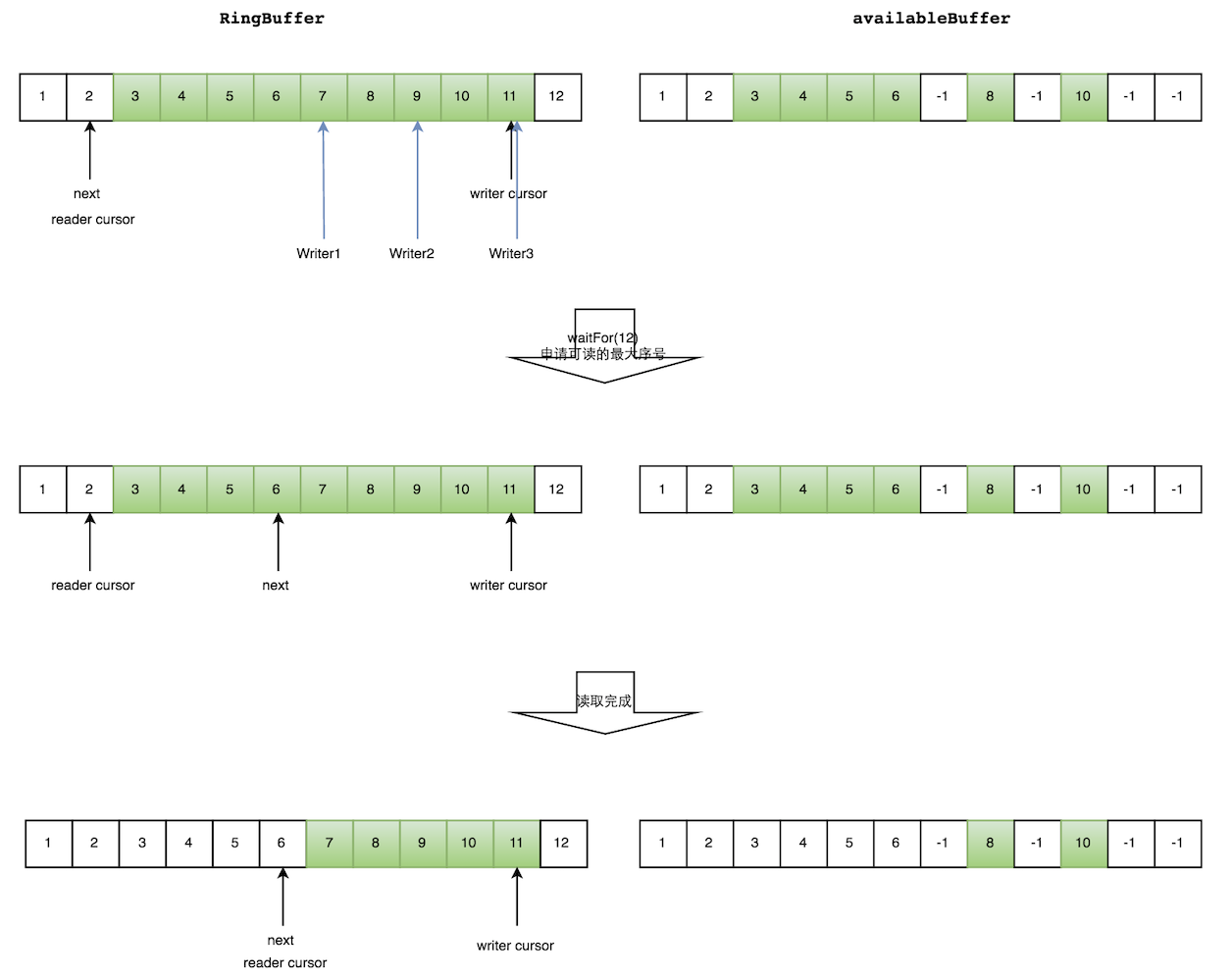
Figure. 2. 拥有一组独立消费者的 Disruptor 示例
使用示例
LMAX 有一个典型应用:
日志处理,将输入数据存放入持久化的日志文件
备份,将输入数据发送给远端服务器
业务逻辑,真正的数据处理工作
图 1 中存在三个事件处理者同时监听 Disruptor,每个 EventHandler 将以相同的顺序同时收到所有在 Disruptor 中可获得的信息(数据),这允许多个消费者进行并行操作。
3.2 关键点分析
预分配的环形数组
从 2.2.1 的分析中,我们知道预分配整个内存空间可以最小化 GC 的代价。同时,预分配的内存是连续的,由于缓存行的存在,数据遍历速度会大大提高。预填充的数组满足上述两个要求。
在初始化环形缓冲区时,Disruptor 通过抽象工厂模式预分配 Entries。当一个 Entry 被声明时,生产者可以将它的数据存进预分配的结构中。元素位置定位
在大多数操作中,计算序列号的余数代价昂贵,其中序列号决定了环形数组中的 slot 位置。将数组长度设置为 2^n,可以通过位运算降低成本。假设环形数组大小 bufferSize 为 8,则游标 index 为 14 时获取映射位置的运算过程如下:Binary(14) = 1110, Binary(8) = 1000
mod(14, 8) = 1110 & 0111 = 0110无锁设计
单生产者情况下,不会发生对 writeCursor 的争用。多生产者情况下,可以使用 CAS 更新 writeCursor,管理下一个可用的 entry。
对于多消费者,Disruptor 定义了一个校验数组 availableBuffer,其大小与环形数组的大小相同。availableBuffer 的初始值为[-1, -1, -1,…, -1],当某个 slot 被写入后,availableBuffer += 1。
- 内存填充
前文中介绍过 Disruptor 框架中 RingBuffer,生产者和消费者都持有一个 Sequence。RingBuffer 缓冲区中,Sequence 标示着写入进度,例如每次生产者要写入数据进缓冲区时,都要调用 RingBuffer.next() 来获得下一个可使用的位置。对于生产者和消费者来说,Sequence 标示着它们的事件序号,来看看 Sequence 类的源码:
1 | class LhsPadding { |
真正使用到的变量value,它的前后空间都由8个long型的变量填补了,对于一个大小为64字节的缓存行,它刚好被填补满(一个long型变量value,8个字节加上前/后个7long型变量填补,7*8=56,56+8=64字节)。这样做每次把变量value读进高速缓存中时,都能把缓存行填充满,保证每次处理数据时都不会与其他变量发生冲突。
3.3 简单示例
demo 代码实现的功能:每10ms向disruptor中插入一个元素,消费者读取数据,并打印到终端。
1 | /** |
根据以上 demo,我们简要分析 Disruptor 的源码。for 循环之前均是一些参数设置,因此我们从 ringbBuffer.next() 开始分析。
3.3.1 next() 方法
单生产者
1 | // SingleProducerSequencer.java |
关键之处如下:
返回的 sequence 对应的 slot 必须已经被所有消费者消费完毕
Util.getMinimumSequence() 会遍历所有消费者使用的 Sequence,并获取其最小值,这是一个比较昂贵的操作,所以将其缓存在本地的 cachedValue 变量中
如果 seq 对应的 slot 还没被消费者消费完毕,说明生产速度快于消费速度,生产者需要原地自旋等待,同时向消费者发送信号,避免消费者睡死过去的情况
多生产者
1 | // MultiProducerSequencer.java |
与单生产者类似,主要是序列值和安全序列值都使用原子变量,解决线程安全问题。同时在赋值时,使用 CAS 操作。
publish() 方法
1 | // SingleProducerSequencer.java |
3.3.2 消费者从 RingBuffer 获取数据
如图所示,读线程读到下标为 2 的元素,三个线程 Writer1/Writer2/Writer3 正在向RingBuffer 相应位置写数据,写线程被分配到的最大元素下标是 11。
读线程申请读取到下标从 3 到 11 的元素,判断 writer cursor>=11。然后开始读取 availableBuffer,从 3 开始,往后读取,发现下标为 7 的元素没有生产成功,于是 WaitFor(11) 返回 6。
然后,消费者读取下标从3到6共计4个元素。
源码分析
TODO
3.3.3 WaitStrategy
源码分析 TODO
4. Conclusion
- Disruptor 通过 3.2 节中的几个关键点实现了无锁编程,并在底层实现中进行了大量优化,值得我们学习。
- 由于 Disruptor 是单机并发队列框架,对分布式系统并不适用。
- 依赖图、等待策略等由于时间问题来不及分析,后续学习过程中补充,并发布到 hio。